Private information retrieval using homomorphic encryption (explained from scratch)
This is a from-scratch explanation of private information retrieval built using homomorphic encryption. I try to assume only a general math / computer science background. To simplify things, my explanations may not always match academic definitions. You can check out this paper or code for more.
Say we want to fetch an article from Wikipedia, but somehow not reveal to the server which one we fetched.
A naive solution is to download and store the entirety of Wikipedia; then, all your queries can be local and the server never learns anything. Unfortunately, this takes a lot of bandwidth and storage (~10 GB), so it isn’t very practical.
Another strawman solution might be to put the articles in buckets, and just send some ‘dummy’ articles along with the true response. This still leaks significant information - over time, or with any additional prior about your behavior, it’s easy to narrow down the set of articles you were really looking at.
It turns out that we can do much better - it is possible to cryptographically guarantee that the server cannot learn anything about your query. In cryptography, this problem is called “Private Information Retrieval”, or “PIR”. In PIR, a client wishes to retrieve the -th item of an -item database hosted on a server, without revealing to the server or downloading the entire database. Crucially, this “query privacy” guarantee should hold even if the server is actively malicious.
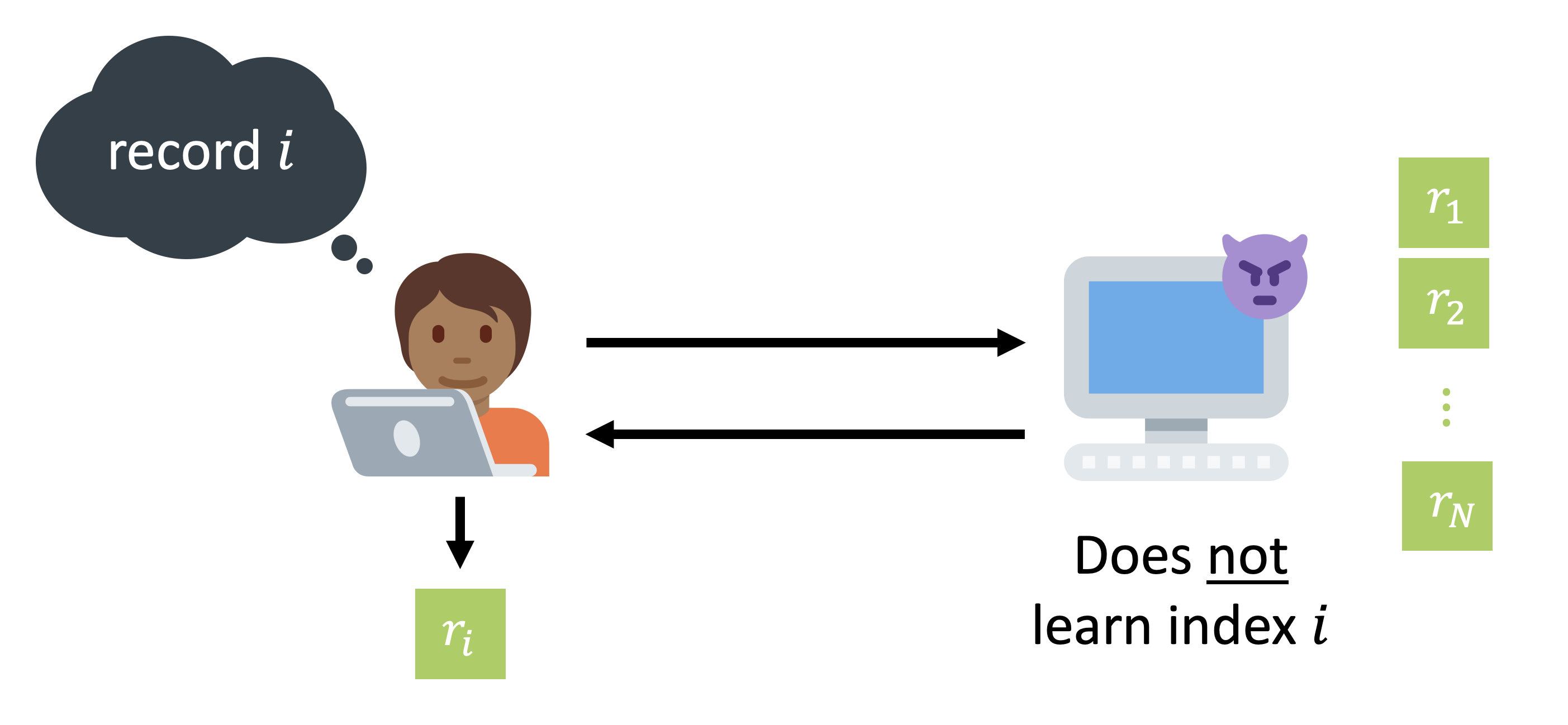
The power of PIR is that it cuts off the flow of data from clients to servers at the source - the server never gets the data in the first place! This is a big deal: we can stop promising not to collect and store data (promises that inevitably get watered down by acquisitions, external pressures, etc), and start cryptographically guaranteeing that there is no data to collect. You can use PIR to build websites that can’t learn the pages you load (private Wikipedia), cryptocurrency block explorers that can’t learn your address (private Bitcoin explorer), and someday, maybe even private search engines or messaging services that can’t learn who you talk to.
In this post, I’ll explain how we can build PIR from scratch. By the end of this article, we’ll have 200 lines of zero-dependency Python that implement a working (though inefficient) PIR scheme.
Constructing PIR using homomorphic encryption
The standard toolkit of normal encryption and hash functions does not yield a workable solution to PIR. However, using a special kind of encryption called “homomorphic encryption”, it is possible to answer a query privately without downloading the entire database. Here is a high-level overview of how a client can privately retrieve the -th item from an -item database; in our example, and :
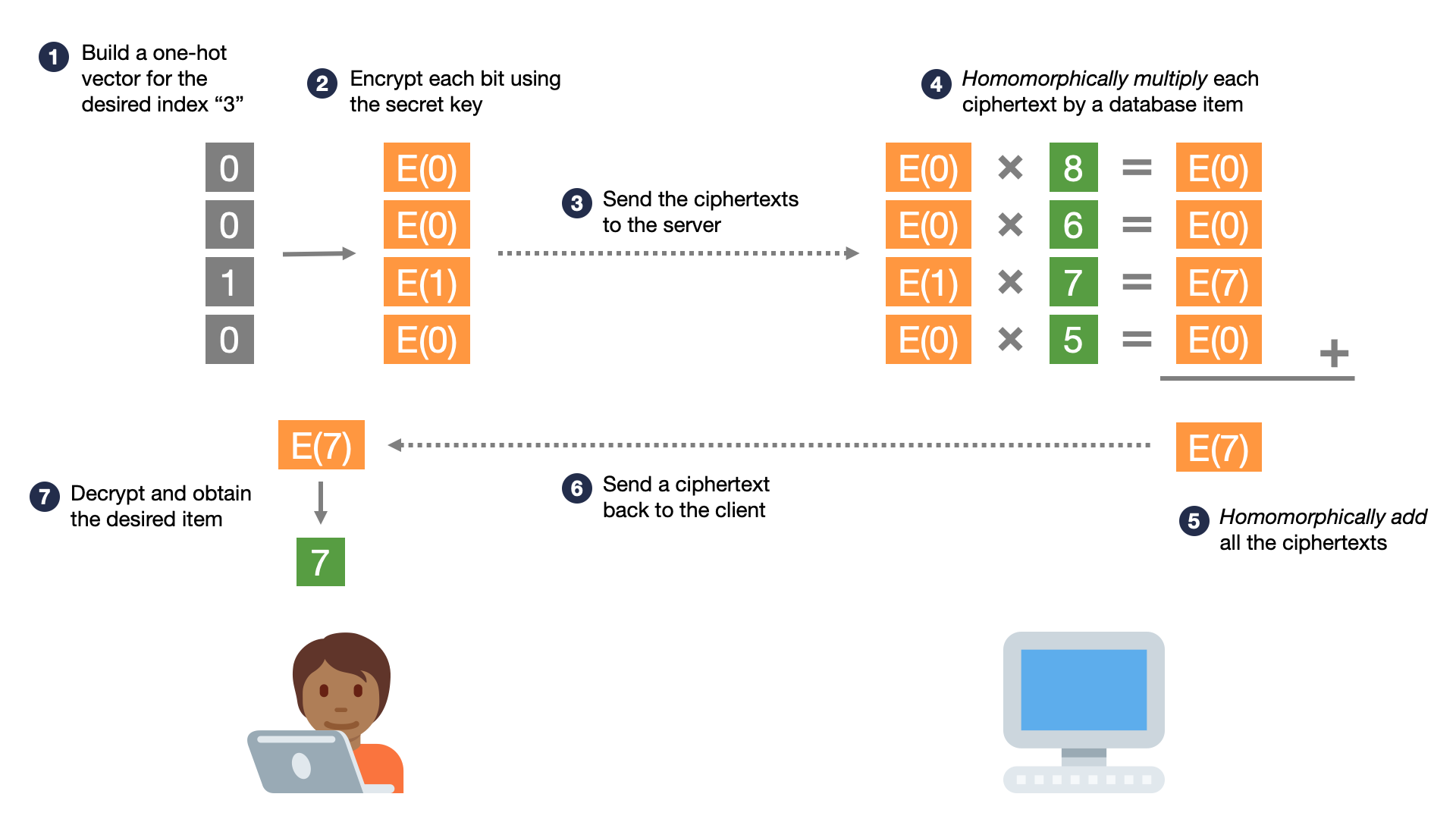
- The client encodes its desired index in a one-hot encoding. That is, it builds a vector of bits, where the -th bit is and the rest are .
- The client generates a homomorphic encryption secret key, and uses it to encrypt each bit, producing ciphertexts, where the -th ciphertext is an encrypted , and the rest are encrypted ’s.
- The client sends this vector of encrypted bits to the server. To the server, this vector of encrypted bits is completely random noise; it cannot learn anything about the encrypted bits.
- The server takes the ciphertexts (each encrypting a bit), and homomorphically multiplies them by the corresponding plaintext database item. This produces a total of ciphertexts, each encrypting either 0 or the desired database item.
- The server homomorphically adds all of these ciphertexts, resulting in a single ciphertext encrypting the desired database item.
- The server sends this single ciphertext to the client.
- The client decrypts this ciphertext and obtains its desired plaintext item.
The special feature of homomorphic encryption is that it is possible to perform the above two bolded operations; specifically:
- Homomorphic addition: If the ciphertext encrypts , and the ciphertext encrypts , then encrypts the value .
- Homomorphic plaintext multiplication: If the ciphertext encrypts and we have some other plaintext , then encrypts the value .
Basically, these properties let the server “add” ciphertexts or “multiply them by plaintexts”, without learning what they encrypt. These properties are not a part of normal encryption schemes - if you try to add ciphetexts in a standard encryption scheme like AES, you will get garbage.
Importantly, aside from the homomorphic properties, homomorphic encryption schemes still satisfy the key property of normal encryption:
- Confidentiality: A ciphertext reveals nothing about the plaintext it encrypts without access to the secret key; this remains true even if an attacker is allowed to repeatedly observe encryptions of known plaintexts. For example, an attacker can observe 10 encryptions of the value “0”, but they will all look different, and the attacker will gain no information about what an 11th ciphertext encrypts.
It’s this property that prevents the ciphertexts sent by the client from leaking information about the query; since the scheme they are encrypted under provides confidentiality, an attacker cannot learn anything about the encrypted bits, and therefore cannot learn anything about the query.
So, to build PIR, we will need a homomorphic encryption scheme which achieves confidentiality, homomorphic addition, and homomorphic plaintext multiplication. Let’s see how to construct one.
I’ve abridged the exact definition of confidentiality for an encryption scheme. There are actually a wide variety of ways to define what makes encryption “secure” in an intuitive sense, and some of them are broken in surprising ways (ex: the AES ECB Penguin). If you’re interested in the formal defitions, check out this lecture or chapter 9 of this free online textbook.
Lattice-based cryptography
To build homomorphic encryption, we will need a new cryptographic scheme. You might already be familiar with symmetric cryptography, like AES or ChaCha, where we want to encrypt data and send it to someone else who has our secret key, and public-key cryptography, like RSA and elliptic curve cryptography (ECC), where we want to allow others to encrypt things to us using only our public key. Ultimately, all these schemes provide variations on confidentiality, but they cannot be used to construct efficient homomorphic encryption. Instead, we will need to learn about a new family of schemes, lattice-based schemes, that can provide both confidentiality and the homomorphic properties we want.
Encryption schemes like RSA or ECC are based on hard problems that cryptographers hypothesize are very difficult to solve. I’m oversimplifying, but the RSA problem boils down to something like:
“Given , where and are large primes, find ”
Cryptographers’ hypothesis for RSA is that given , finding (without knowing ) will take an amount of computation that is exponential in the size of the number n (in bits). The hard problem that ECC is based on is more complicated (see this detailed explanation for more).
When we say that a problem is “hard” here, we mean something more than the colloquial meaning of “it’s not easy to solve”. The technical meaning of “hard” in this context is more like “taking time exponential in the size of the problem”1. To avoid getting into complexity theory that I barely understand, we’ll focus on the most concrete requirement: for a specific instance of a problem to be considered “hard”, it should take at least basic operations (addition, multiplication, etc) to solve it using the best known algorithms. You might ask, “Why ?”; it is a somewhat arbitrary value, but it’s widely used across academia and industry, and current estimates indicate that it would take all of the computing power on Earth working for millions of years to perform operations. So, we say that any problem which takes operations to solve is “hard”, and in practice impossible to solve.
Lattice-based cryptography is based on a different class of hard problem than RSA and ECC, (unsurprisingly) called lattice problems. We will focus on a single hard problem, called the “learning with errors” problem, or LWE. I think that this problem is actually in some ways simpler to understand than the hard problems that underly RSA and ECC, and we can use it to build efficient homomorphic encryption.
Post-quantum cryptography
In what is basically an unfortunate coincidence, both the RSA and ECC problems can be solved quite easily by a large-enough quantum computer. Lattices, as far as we know today, cannot, so another motivation for lattice-based cryptography is that it will still be secure if someone builds a large quantum computer (there’s even a global competition to choose a secure post-quantum encryption scheme).
Learning with errors (LWE)
The “Learning with errors” (“LWE”) problem was introduced by Oded Regev in 2005, and has since been used to build many advanced cryptographic schemes, of both theoretical and practical interest.
Some preliminaries: assume that is some prime number. We write to represent the set of integers modulo ; when we say some value , we mean that is an integer in the range . We assume that all operations between elements of are modulo ; so, if we have and , then and . We write to represent an -element vector, and to represent an matrix. When we say that we “sample” vectors or matrices “at random”, we mean that we choose a random number in the range for each element of the vector or matrix. We use , and for our toy examples, but “hard” instances of the problem have larger values.
Now, imagine someone samples a vector and a matrix uniformly at random.
Say they give us and the matrix-vector product . Can we determine ?
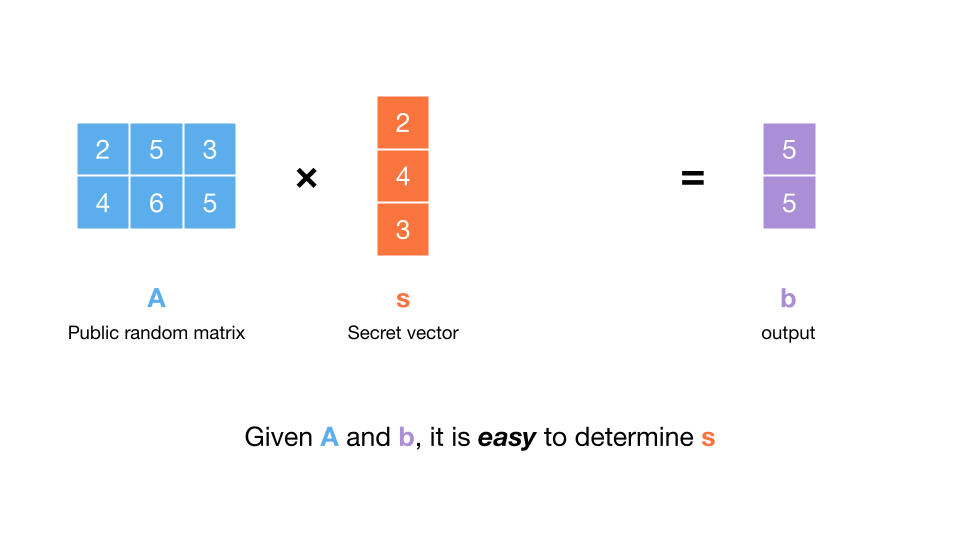
The answer is, with overwhelming probability, yes, it will be easy to dermine . How? We can compute the matrix inverse of , and then multiply this by . This will give us since . The matrix inverse will exist as long as the determinant of is not zero, which is almost certainly true, since was chosen uniformly at random. Computing the matrix inverse is also not difficult, so this is not a ‘hard’ problem, and so it’s not one we can base cryptography on.
Things get more interesting when we make a small change to the problem. Instead of sending us , what if instead they make things harder by injecting some error into ? Specifically, if they send us , for some error vector , the problem becomes suprisingly hard. This is because multiplying by the matrix inverse doesn’t work well in the presence of even a small amount of error. The error can be sampled a number of ways, but for now imagine that it is chosen uniformly over a small range (much less than ).
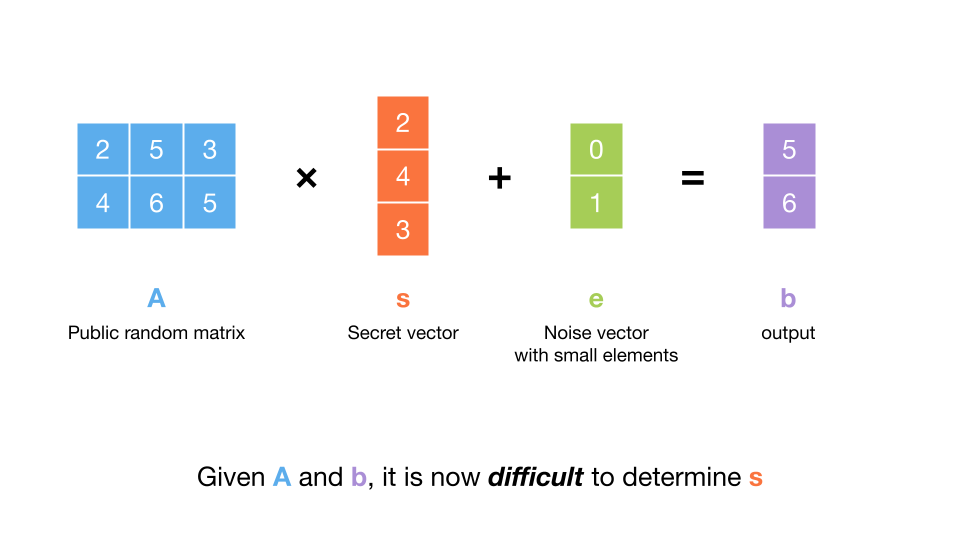
This problem is called “learning with errors”, or LWE, since we are trying to learn given some data that contains errors. Each row of the output can be called an “LWE sample”, since it is a noisy ‘observation’ of the dot product of a row of and . For this reason, the error is also often referred to as “noise”, and the distribution it is sampled from is called the “noise distribution”. The challenge is to determine from at most LWE samples.
This is thought to be very hard, even for surprisingly small choices of the parameters. For example, cryptographers think that solving this problem for , , and error sampled uniformly from is difficult (in fact, NIST is standardizing a scheme with similar parameters for its resistance to even a large quantum computer). We think that this instance of the problem is hard no matter how many LWE samples an attacker gets access to, so we would say that for these parameters. Concretely, calling these parameters “hard” means that the following problem is hard (practically impossible) to solve:
- Generate a vector of random numbers, each in the range , and call this .
- Generate a vector of random numbers, each in the range , and call this .
- Generate a random number, from the set , and call this .
- Compute , where is the dot product.
- Output .
- You may repeat steps 2-5, getting a new each time, as many times as you want.
- Figure out .
So far, we’ve looked at a “search” version of the LWE problem - we are trying to ‘find’ given noisy samples. To build encryption using LWE, it will be useful to work with a related version of LWE which we’ll call the “distinguishing” problem, which is also considered hard. In this version of the problem, we have to ’tell the difference’ between an where , as above, and an where was picked totally randomly. That is, we are given , and we need to output a guess as to whether was sampled the ‘LWE way’, or whether was sampled randomly. What cryptographers hypothesize is that, for the the same choices of and as before, there is no algorithm that can output a correct guess with better than extremely low () probability. The assumption that this problem is hard, which we can use to build cryptography, is called the decision LWE assumption, or ‘DLWE’ (the decision variant was actually proven to be equivalent to the search variant in most cases, so it is often also referred to as ‘LWE’).
To be concrete, let’s try to formalize our definition of the DLWE assumption. If we have the following functions in pseudocode:
def sample_true():
A = random_matrix(n, n)
s = random_vector(n)
e = random_noise_vector(n)
b = A * s + e
return (A, b)
def sample_random():
A = random_matrix(n, n)
b = random_vector(n)
return (A, b)
Then we can first informally state the assumption as:
It is “hard” to tell the difference between the outputs of
sample_true()andsample_random().
Let’s try formalize this statement. Say we are given an algorithm algorithm that takes in the result of calling either sample_true() or sample_random(), and outputs a bit indicating a guess for which function produced it (say 0 means sample_true(), and 1 means sample_random()). Now, we’d like to quantitatively measure how well algorithm can “tell the difference” between the functions. We can run the following experiment on it many times:
def experiment(algorithm):
bit = random_bit()
if bit == 0:
guess = algorithm(sample_true())
else:
guess = algorithm(sample_random())
return guess == bit
The probability that experiment returns true will be something between 1/2 and 1 (we know it is at least 1/2, since even an algorithm that just always outputted 1 would be correct half of the time). The higher this probability, the better algorithm is at “telling the difference”. Now, we can state the DLWE assumption formally:
The DLWE assumption for a security parameter is: for any
algorithmthat performs less than operations,experiment(algorithm)will succeed with a probability less than .
The security parameter captures formally the idea of it being “very hard” to distinguish the outputs of these functions - for example, if the DLWE assumption holds for , then any attacker that can perform less than operations cannot effectively distinguish sample_true() from sample_random(). This concept of LWE samples being “computationally indistinguishable from random” is the key property that makes them useful for encryption. The word “operation” in our definition is a bit quishy - let’s just think of this as some kind of basic addition or multiplication, or if you prefer, a logicial gate in a circuit representing the computation.
I will omit a deeper explanation of why the DLWE assumption holds, and under which parameters. This is a still-active area of research, and the mathematics is complicated. We will just assume that for some choices of , , and the noise distributuion, DLWE is completely infeasible to solve.
Regev’s Scheme: Homomorphic Encryption from LWE
Now that we understand LWE, let’s see how we can use it to build homomorphic encryption. To start, we will just use LWE to build normal encryption, and then afterwards, we’ll try to make it homomorphic.
Say we have a secret key , sampled uniformly at random from . Then the DLWE assumption states that, for a random matrix and noise vector , the vector is indistinguishable from random. How can we use this to build encryption?
Let’s start simply and assume we’d like to encrypt a single bit . How can we use the fact that is indistinguishable from random to encrypt ? Well, if I sampled a truly uniform random element from , and then gave you , you would have no hope of learning anything about (remember that is the integers mod q, so it “wraps around”). This is because is chosen randomly, so no matter what is, still “looks” random; cryptographers call this “blinding”.
Now, we know that is not actually random; but, by the DLWE assumption, to an attacker that does not no the secret key, it might as well be - it is indistinguishable (in a feasible amount of operations) from random. Let’s try to blind using . Since is just a bit, we’ll want to set our for encryption - this makes a single value in , so that we can encrypt as the ciphertext .
Then what if we encrypt the message with the ciphertext ? We can make a very convoluted argument (a proof by contradiction) that, by the DLWE assumption, does not reveal anything about . If proofs make you fall asleep, feel free to skip it; it’s not important for the rest of our explanation.
Proof
Say there was an algorithm
algAthat could figure out from , where is an LWE sample, and is a single bit. Then we can construct an algorithmalgBthat can “break” DLWE. Specifically:def algB((A, b)): x = random_bit() guess = algA(A, b + x) if guess == x: return 0 else: return 1Recall that to “break” DLWE, we need to run the
experimentfunction (see above) onalgB, many times, and have it succeed more than with a probability significantly larger than (specifically, larger than ). Now, let’s walk through what happens when we runexperiment(algB), depending on thebitchosen in the first line ofexperiment:
- If
bitinexperimentis0, then we will passalgBa “true” LWE sample, and (by assumption)algAwill work correctly, soguess == x, and we will return0.- If
bitinexperimentis1, so we passalgBa completely random(A, b). Then we also end up passing in two random values toalgA; since the input is completely random,algAmust guess correctly exactly half the time, so we will output a random bit.To summarize, if
bitis0, thenalgBwill always correctly output0, andexperimentwill returnTrue. If thebitis1, thenalgBwill output a random bit, and soexperimentwill returnTruewith probability 1/2. Then the total probability that theexperimentreturnsTrueis .Since is (much) bigger than ,
algBbreaks the DLWE assumption.We have shown that any efficient algorithm that could figure out from would violate the DLWE assumption. Then, since we assume DLWE is true, no efficient (running in less than operations) algorithm can figure out from .
If the above proof is interesting to you, then you might really like academic cryptography - this online cryptography class from Stanford is a great introduction. The above kind of proof is called a “security reduction”, since it ‘reduces’ the security of the encryption scheme to the DLWE problem. The basic outline of the argument is:
- We first show: “If you break our scheme, then you can break DLWE”
- Then we have really also proved the contrapositive: “If it’s difficult to break DLWE, then it must be difficult to break our scheme”
If the above proof seems like a very complicated way to express something simple, you might still like cryptography, but maybe not the proofs…
So, you should now be convinced that just adding our message to in the LWE sample gives us a ciphertext that reveals nothing about to an attacker. We are missing the other piece, though - how do we actually decrypt this ciphertext using the secret key?
To decrypt the ciphertext using secret key , we can compute , and get:
This gives us something very close to what we want. Our goal is recover , but we have gotten . Recall that is some noise, sampled from the noise distribution, so it is not uniformly random. Still, since , we’re not going to be able to extract the message out of the value , since our noise distribution is a centered distribution with small range. Recall our example parameters of , , and a noise distribution of ; it is not possible to recover given , since is 0 or 1, and is a random integer between -3 and 3.
Here, the value is divided by 2, rounded down to the nearest integer. The point of doing this is that now, when we decrypt with , we will now get . If is sampled from a small range, much smaller than , then it’s now possible to recover from - we just need to “discard the low bits” of noise. Basically, we should see if is closer to , in which case , or , in which case . Concretely, we can calculate , where just denotes rounding. As long as is within the range , the decryption will be correct.
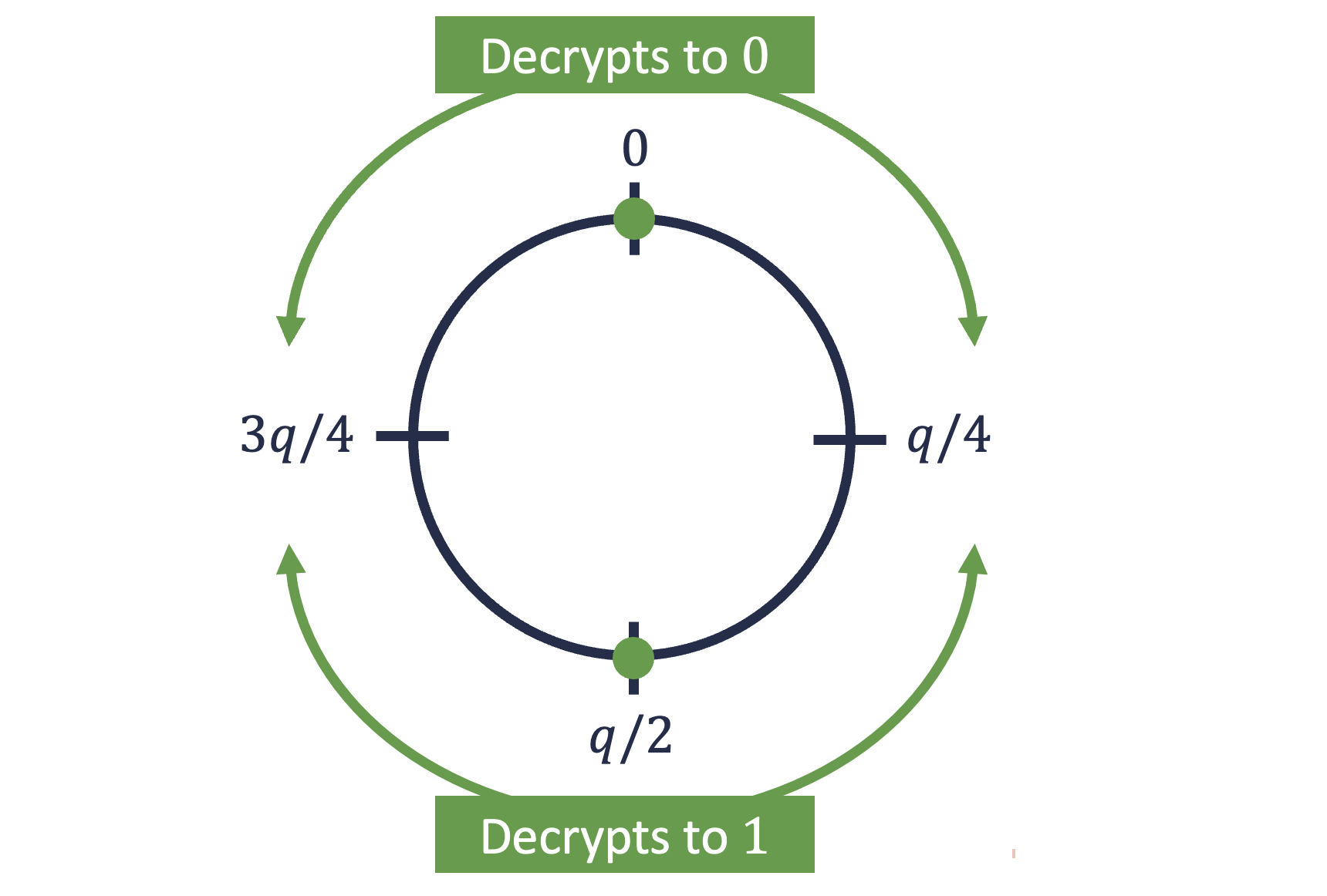
So, our full scheme (a version of Regev’s original one) looks like:
n = 512
q = 3329
noise_distribution = [-3, 3]
def get_LWE_sample(s):
A = random_matrix(n, n)
e = random_noise_vector(n)
b = A * s + e
return (A, b)
def keygen():
s = random_vector(n)
return s
def encrypt(s, x):
assert x == 0 or x == 1
(A, b) = get_LWE_sample(s)
c = b + floor(q / 2) * x
return (A, c)
def decrypt(s, (A, c)):
raw = c - A * s
return round(raw * 2 / q)
Notice that the ciphertexts in this scheme are very large compared to what they encrypt. To encrypt a single bit, our scheme takes bits! This is much worse than AES, for example, where ciphertexts are basically the same size as plaintexts. There are effective techniques to make the ciphertext sizes in LWE-base encryption smaller, but we won’t cover them in this post.
Homomorphic addition
So, we’ve constructed a “confidential” scheme, and now we’d like to make it homomorphic - this was the entire point of learning about LWE and Regev’s scheme!
The good news is we don’t have to do much. Let’s say we have two ciphertexts and which encrypt messages and , all under the secret key . Then we know that the following will be true, for some noises and :
Basically, we are rewriting the fact that if you decrypt , you will get , and similiarly for .
Then what happens if we just naively add the ciphertexts? We can construct a new ciphertext by just adding the and components separately: . If we try to decrypt it:
We get the sum of the messages, , with noise . This is exactly what we want! This means if we add a ciphertext for and a ciphertext for , we will get a new ciphertext for . When we add two ciphertexts, both encoding ’s, we will get a ciphertext encoding (the messages are bits, and the addition of bits gets performed like a XOR operation) 2.
Now, we could send the server a bunch of encrypted bits, and it could respond with the XOR of all of these bits, without ever learning the input bits or the output bit. Essentially, we could “outsource” the computation (just XOR’ing all the bits)
A really interesting thing is happening to the noise when we do homomorphic addition. Remember that for our example parameters, the noise distribution is . This means that both and fall in the range . But what about their sum, ? Well, their sum can fall in a wider range, . Luckily, even this is not a wide enough range to make our message bit unrecoverable - we chose , and as long as the noise is less than , we should decrypt properly. But, notice that this is not an unlimited budget; if we kept adding up ciphertexts, we would eventually have a noise range that exceeded . At that point, if we tried to decrypt, there’s a chance we would get an incorrect message.
If we add more than ciphertexts (), there is a (very small) chance that decryption could fail. If you enjoy statistics, you could try using the Irwin-Hall Distribution to figure out the exact probability of decryption becoming incorrect given some number of ciphertext additions.
This idea that the noise “grows” as you perform homomorphic operations on the ciphertexts is fundamental - one main challenge of homomorphic encryption is controlling “noise growth” to be able to perform computation without letting the noise grow so large that you end up with incorrect results.
So, we have achieved homomorphic addition! As we outlined at the beginning, this is one crucial property needed to build PIR.
Homomorphic plaintext multiplication
Recall the two key properties that we wanted from a homomorphic encryption scheme:
- Homomorphic addition: If the ciphertext encrypts , and the ciphertext encrypts , then encrypts the value .
- Homomorphic plaintext multiplication: If the ciphertext encrypts and we have some other plaintext , then encrypts the value .
We’ve already shown how to achieve homomorphic addition. Now, we can turn our attention to homomorphic plaintext multiplication.
Thinking more deeply about these two properties, you might notice that they are related. If you add a ciphertext to itself, this is equivalent to multiplying the ciphertext by the plaintext value ‘2’.
In our scheme that encrypts only bits, the relationship is actually even simpler. Remember that in our scheme so far, every plaintext value is just a bit. So, homomorphic plaintext multiplication really just entails being able to multiply a ciphertext by a plaintext or . As it turns out, these are straightforward already: to multiply a ciphertext by the plaintext , just zero out the entire ciphertext, and to multiply a ciphertext by the plaintext , just don’t do anything to the ciphertext. So, we already have homomorphic plaintext multiplication! Now, we have all the components needed to finally build PIR.
Back to PIR, finally
We now have a complete and secure PIR scheme, though it is quite inefficient. Here is the complete scheme in action:
n = 512
q = 3329
noise_distribution = [-3, 3]
num_items_in_db = 50
desired_idx = 24
db = [random_bit() for i in range(num_items_in_db)]
def generate_query(desired_idx):
v = []
for i in range(num_items_in_db):
bit = 1 if i == desired_idx else 0
ct = encrypt(s, bit)
v.append(ct)
return v
def answer_query(query, db):
summed_A = zero_matrix(n, n)
summed_c = zero_vector(n)
for i in range(num_items_in_db):
if db[i] == 1:
(A, c) = query[i]
summed_A += A
summed_c += c
return (summed_A, summed_c)
s = keygen()
query = generate_query(desired_idx)
print("Sending the query to the server...")
answer = answer_query(query, db)
print("Got the answer back from the server...")
result = decrypt(s, answer)
print("The item at index %d of the database is %d", desired_idx, result)
assert result == db[desired_idx]
print("PIR was correct!")
You can also run this code in your browser and try it out yourself! It’s 200 lines of Python with zero dependencies.
To privately retrieve a single bit (again, it’s not very efficient…) from the database, we upload a vector of ciphertexts encrypting bits (where only one encrypts a , and the rest encrypt ’s), multiply each one by a plaintext database bit, and then add it all up. The final ciphertext can get sent back to the client, and when they decrypt they will get the desired database bit.
We should take a moment to savor how we have actually solved a problem using cryptography that intuition would imply might be totally impossible. It really is not intuitive that there is any way to privately get a subset of the data on a server without just downloading everything. We also learned from the ground up why this scheme is secure, and how we could prove this formally.
Of course, before we congratulate ourselves too much, we might realize our scheme is quite impractical. There are several glaring problems:
- You have to upload more data (in the query) than the size of the entire database (!)
- You can only retrieve one bit at a time
The barriers to practicality for PIR are formidable; so formidable, in fact, that as recently as 2007, researchers hypothesized that PIR might never be practical for any real-world scenario.
The wonderful news is that the research has come a long way, and there are now many practical and efficient PIR schemes! See Spiral, SimplePIR/DoublePIR, OnionPIR, FastPIR, SealPIR, XPIR, and more.
Making the toy scheme we’ve outlined here practical and efficient is no small task, so I will save that for another post. I will show how we can use homomorphic multiplication to make the queries smaller, and how we can extend the scheme to encrypt more than just a single bit per ciphertext. In the meantime, try reading Wikipedia or checking a Bitcoin address balance using PIR. If you have questions or comments, email me at founders@usespiral.com or tweet @SpiralPrivacy.
Thank you to Aakanksha and others for their helpful comments.
-
We do not mean NP-hard; the exact reasons for this are complex, but I’ll summarize by saying that (most) cryptography is built on problems that we hypothesize are hard, not on problems that we have proofs of hardness for. This is why, every once in a while, people find out that a problem we thought was difficult was not. ↩︎
-
A careful reader might notice that if is odd, the sum of two ciphertexts encoding ’s will not quite be a ciphertext encoding . There will be some small rounding error introduced by this - specifically, of magnitude , since when is odd, . This is small, and can just be thought of as part of the noise. ↩︎